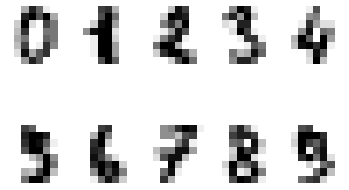Task: Split the iris data into training and test. Predict on test
# Split into training and test setX = iris['data']y = iris['target']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size =0.3, random_state=42)# Create a k-NN classifier with 7 neighbors: knnknn = KNeighborsClassifier(n_neighbors=6)# Fit the classifier to the training dataknn.fit(X_train, y_train)# Print the accuracyprint(knn.score(X_test, y_test))
1.0
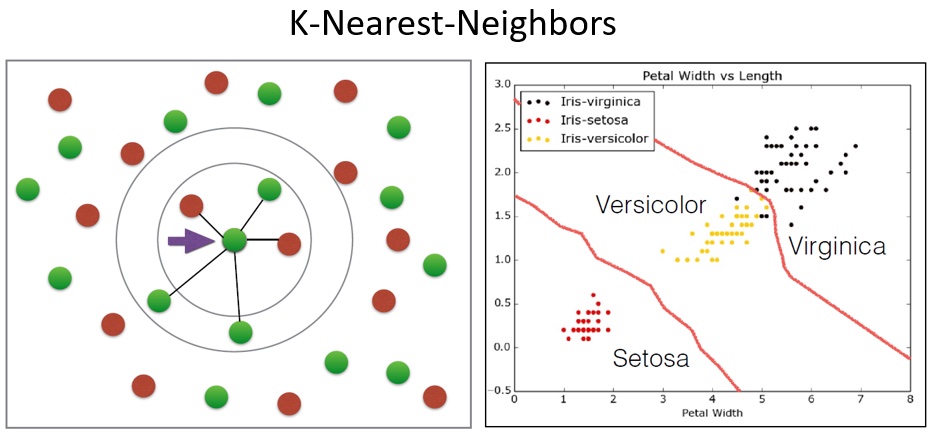
Simple Idea, no modeling assumptions at all !! Think about the following:
What is “the model”, i.e. what needs to be stored ? (coefficients, functions, …)
What is the model complexity ?
Does this only work for classification ? What would be the regression analogy ?
What improvements could we make to the simple idea ?
In the modeling world:
linear ?
local vs. global
memory/CPU requirements
wide versus tall data ?
Handwritten Digits
digits = datasets.load_digits()import matplotlib.pyplot as plt#how can I improve the plots ? (i..e no margins, box around plot...)plt.figure(1)for i in np.arange(10)+1: plt.subplot(2, 5, i) plt.axis('off')#plt.gray() #plt.matshow(digits.images[i-1]) plt.imshow(digits.images[i-1], cmap=plt.cm.gray_r, interpolation='nearest')plt.show()
# Create feature and target arraysX = digits.datay = digits.target# Split into training and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size =0.2, random_state=42, stratify=y)# Create a k-NN classifier with 7 neighbors: knnknn = KNeighborsClassifier(n_neighbors=7)# Fit the classifier to the training dataknn.fit(X_train, y_train)# Print the accuracyprint(knn.score(X_test, y_test))
0.9833333333333333
# Big Confusion Matrixpreds = knn.predict(X_test)pd.crosstab(preds,y_test)
col_0
0
1
2
3
4
5
6
7
8
9
row_0
0
36
0
0
0
0
0
0
0
0
0
1
0
36
0
0
0
0
0
0
2
0
2
0
0
35
0
0
0
0
0
0
0
3
0
0
0
37
0
0
0
0
0
0
4
0
0
0
0
36
0
0
0
0
1
5
0
0
0
0
0
37
0
0
0
0
6
0
0
0
0
0
0
35
0
0
0
7
0
0
0
0
0
0
0
36
1
0
8
0
0
0
0
0
0
1
0
32
1
9
0
0
0
0
0
0
0
0
0
34
Task
Construct a model complexity curve for the digits dataset! In this exercise, you will compute and plot the training and testing accuracy scores for a variety of different neighbor values. By observing how the accuracy scores differ for the training and testing sets with different values of k, you will develop your intuition for overfitting and underfitting.
# # Setup arrays to store train and test accuracies# neighbors = np.arange(1, 20)# train_accuracy = np.empty(len(neighbors))# test_accuracy = np.empty(len(neighbors))# # # Loop over different values of k# for i, k in enumerate(neighbors):# # Setup a k-NN Classifier with k neighbors: knn# knn = KNeighborsClassifier(___)# # # Fit the classifier to the training data# ___# # #Compute accuracy on the training set# train_accuracy[i] = ___# # #Compute accuracy on the testing set# test_accuracy[i] = ___# # # Generate plot# plt.title('k-NN: Varying Number of Neighbors')# plt.plot(___, label = 'Testing Accuracy')# plt.plot(___, label = 'Training Accuracy')# plt.legend()# plt.xlabel('Number of Neighbors')# plt.ylabel('Accuracy')# plt.show()
Further Reading and Explorations: * Read about “one versus all” pitted against multinomial. Check out this notebook. * Read about marginal probabilities.
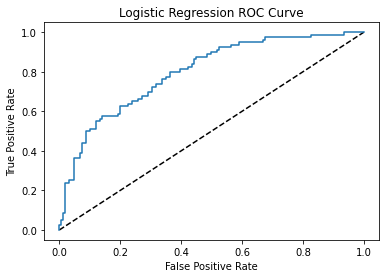
ROC Curves
Simplest to go back to 2 labels from lesson 7:
iris = datasets.load_iris()X = iris["data"][:,3:]y = (iris["target"]==2).astype(int)# Split into training and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size =0.3, random_state=42)log_reg = LogisticRegression()log_reg.fit(X_train,y_train)y_pred = log_reg.predict_proba(X_test) y_pred_prob = y_pred[:,1]from sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixprint(confusion_matrix(y_test, y_pred_prob >0.25 ))print(confusion_matrix(y_test, y_pred_prob >0.5 ))print(confusion_matrix(y_test, y_pred_prob >0.75 ))
[[24 8]
[ 0 13]]
[[32 0]
[ 0 13]]
[[32 0]
[ 4 9]]
The need for more sophisticated metrics than accuracy and single thresholding
This is particularly relevant for imbalanced classes, example: Emails
Spam classification
99% of emails are real; 1% of emails are spam
Could build a classifier that predicts ALL emails as real
99% accurate!
But horrible at actually classifying spam
Fails at its original purpose
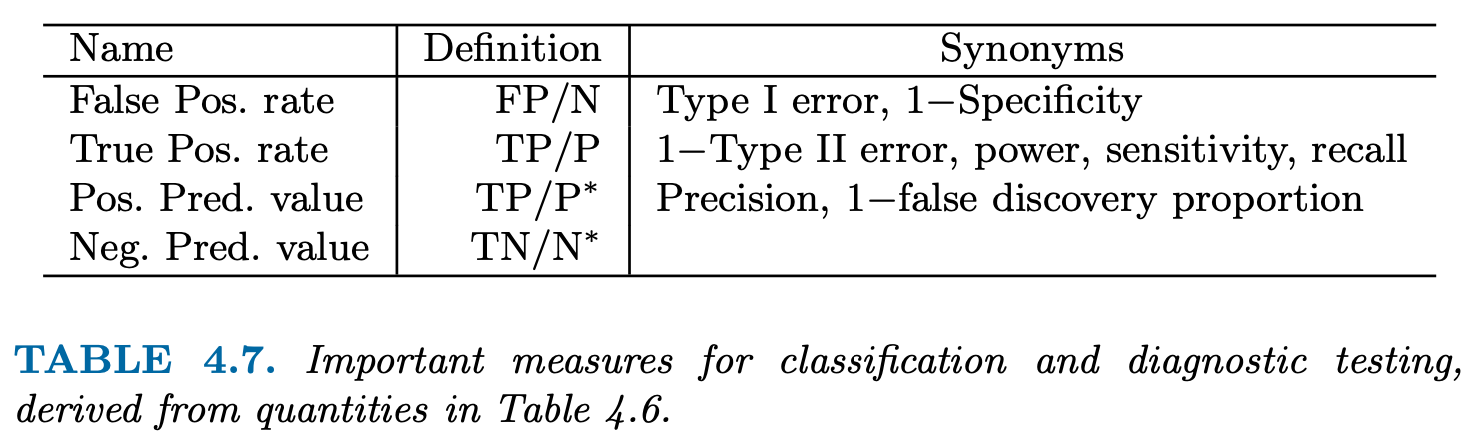
Metrics from CM
Precision: \(\frac{TP}{TP+FP}\)
Recall: \(\frac{TP}{TP+FN}\)
F1 score: \(2 \cdot \frac{precision \cdot recall}{precision + recall}\)
The F1 score is the harmonic average of the precision and recall, where an F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0. () - High precision: Not many real emails predicted as spam - High recall: Predicted most spam emails correctly
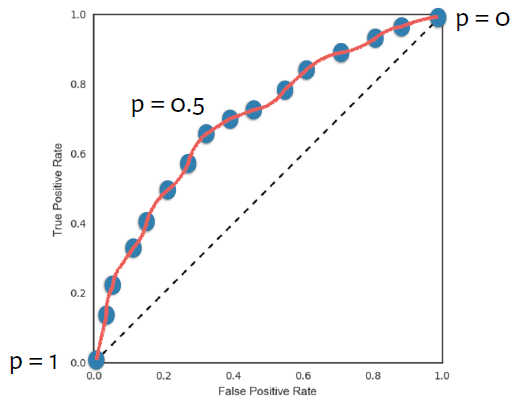
But we still need to fix a threshold for any of the metrics above to work !
Wouldn’t it be best to communicate the prediction quality over a wide range (all!) of thresholds and enable the user to choose the most suitable one for his/her application ! That is the idea of the Receiver Operating Characteristic (ROC) curve!
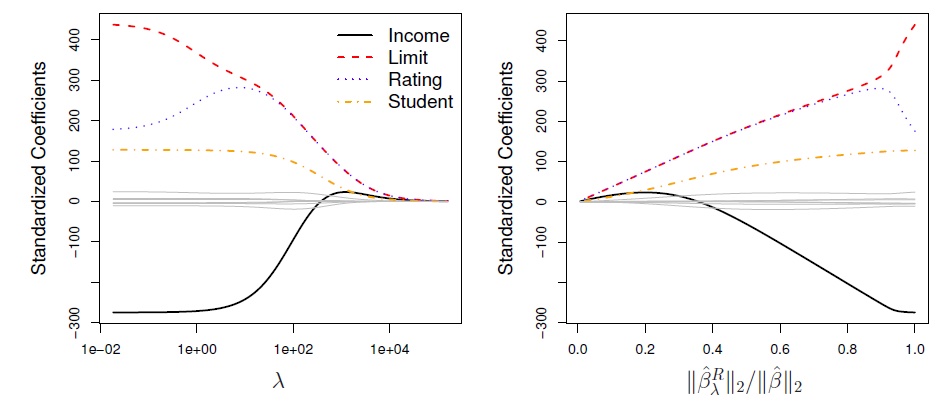
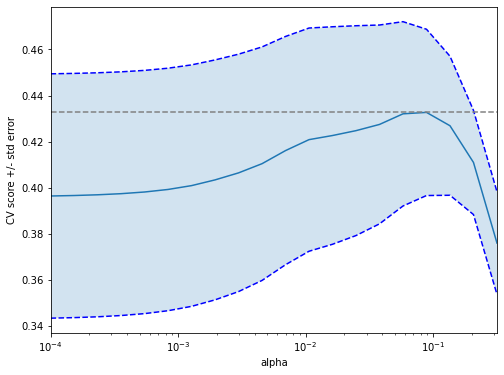
Recall: Linear regression minimizes a loss function - It chooses a coefficient for each feature variable - Large coefficients can lead to overfitting - Penalizing large coefficients: Regularization
Detour: \(L_p\) norms
http://mathworld.wolfram.com/VectorNorm.html
Our new penalty term in finding the coefficients \(\beta_j\) is the minimization
Instead of obtaining one set of coefficients we have a dependency of \(\beta_j\) on \(\lambda\):
from sklearn.linear_model import RidgeX_train, X_test, y_train, y_test = train_test_split(X, y,test_size =0.3, random_state=42)ridge = Ridge(alpha=0.1, normalize=True)ridge.fit(X_train, y_train)ridge_pred = ridge.predict(X_test)#?does this automatically take care of nromalization ??#Returns the coefficient of determination R^2 of the prediction.ridge.score(X_test, y_test)ridge_pred[0:5]
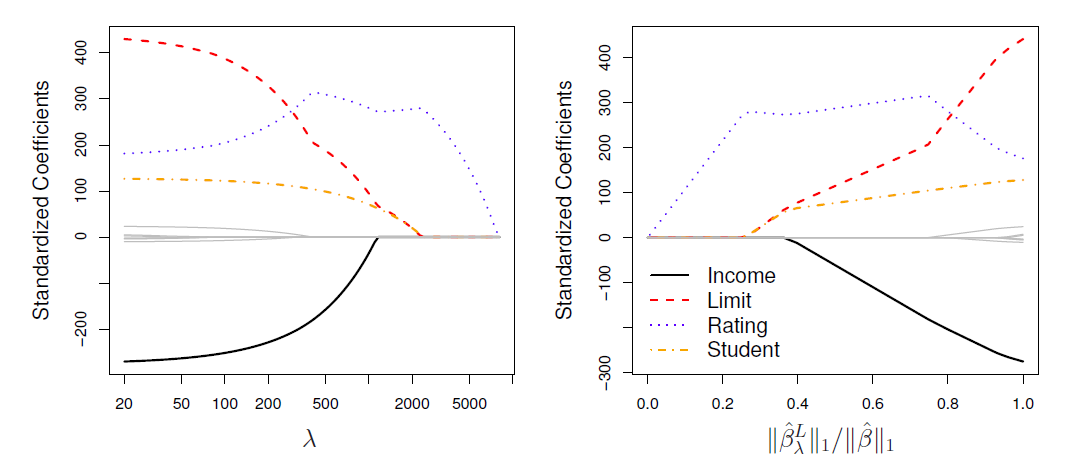
(Comment: LASSO = “least absolute shrinkage and selection operator”)
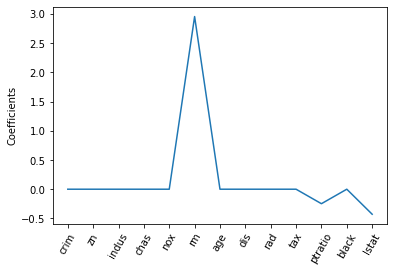
from sklearn.linear_model import Lassolasso = Lasso(alpha=0.1, normalize=True)lasso.fit(X_train, y_train)lasso_pred = lasso.predict(X_test)#Returns the coefficient of determination R^2 of the prediction.lasso.score(X_test, y_test)lasso.coef_
(It seems that \(\lambda\) is often referred to as \(\alpha\))
From sklearn.linear_model:
LassoCV
RidgeCV
GridSearchCV
from sklearn.linear_model import RidgeCVreg = RidgeCV(alphas=[1e-3, 1e-2, 1e-1, 1],store_cv_values =True)reg.fit(X, y)reg.score(X, y)reg.cv_values_#Open Questions: #1. how to extract all scores, possibly even the individual folds?#2. What is the optimal alpha ??#reg.cv_values_
with the Ridge penalty parameter \(\lambda_R \equiv \frac{1}{2} \lambda (1-\alpha)\) and the lasso penalty parameter \(\lambda_L \equiv \alpha \lambda\).